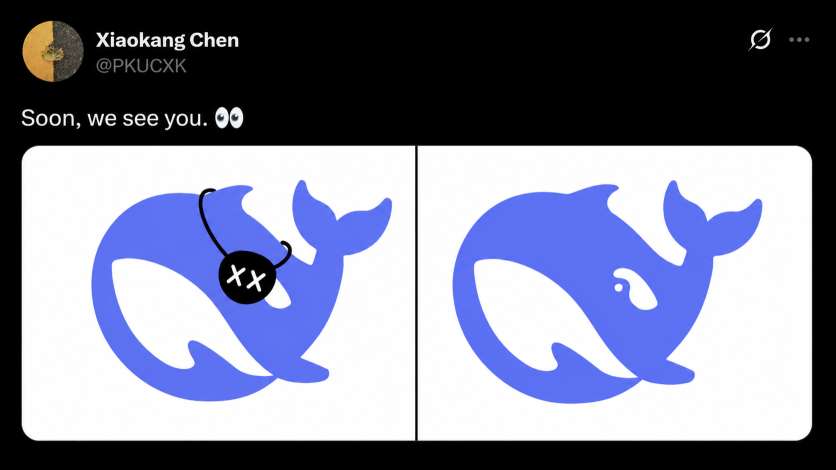
The accompanying caption reads: “Soon, we see you. 👀”
While minimal in presentation, the message has fueled widespread speculation that DeepSeek may be preparing to reveal a major upgrade in its multimodal capabilities.
From Strong Text Models to Multimodal Ambitions
DeepSeek has recently released its most capable models to date, including DeepSeek V4 Pro and DeepSeek Flash. These models are widely regarded as highly competitive in the current AI landscape, with performance that in some cases approaches GPT-4-class systems and narrows the gap with premium reasoning models such as Claude Opus (non-thinking mode comparisons).
From personal testing experience, I have used DeepSeek V4 Pro extensively, processing over 35.7 million tokens in total usage. The model is particularly impressive in long-context reasoning, coding tasks, and maintaining coherence across extended conversations. At scale, its strengths become more evident, especially in efficiency and consistency.
However, one key limitation remains clear:
❌ DeepSeek models currently do not support image understanding or OCR (Optical Character Recognition).
This means the model is still unable to:
- Read text embedded in images
- Interpret screenshots or scanned documents
- Perform visual reasoning over charts, diagrams, or PDFs
In an increasingly multimodal AI ecosystem, this remains a significant gap.

The Whale With Eyes: Symbolism or Signal?
The recently shared visual from Chen Xiaokang presents a split concept:
- On one side, the DeepSeek whale appears without eyes
- On the other, the whale is shown with a visible eye
This subtle transformation has led to speculation that it may symbolize an upcoming capability expansion—specifically, the addition of “vision” to DeepSeek’s models.
The phrase “Soon, we see you” has further reinforced the interpretation that OCR or broader multimodal functionality could be in development.
While there has been no official confirmation, the timing and symbolism have naturally attracted attention.
Why OCR and Vision Matter in AI
If DeepSeek were to introduce OCR and image understanding capabilities, it would represent a major functional leap.
Such capabilities would enable:
- Extraction of text from images and scanned documents
- Interpretation of screenshots and UI content
- Understanding of charts, tables, and diagrams
- More capable document and research assistants
What This Could Signal
If the visual teaser reflects real product direction rather than purely symbolic branding, DeepSeek may be moving toward:
- A multimodal model upgrade combining text and vision
- A vision-enabled API for developers
- A unified AI system capable of cross-modal reasoning
Given the rapid pace of DeepSeek’s recent releases, such an evolution would not be unexpected.
This would position DeepSeek more directly within the competitive multimodal AI space, alongside systems already integrating vision-language capabilities.
The AI industry is steadily shifting beyond text-only intelligence. The next frontier is systems that can see, interpret, and reason about the visual world.
DeepSeek’s whale image may appear simple, but it has triggered meaningful speculation about what comes next.
If the whale is indeed “growing eyes”…
It may signal DeepSeek’s entry into full multimodal capability—and a new phase in its evolution.